
Large Language Models (LLMs): Complete Guide for AI Engineers
- Introduction & Executive Summary
- Part 1: Foundations of Large Language Models
- Chapter 1: What are LLMs?
- Chapter 2: Historical Context & Evolution
- Chapter 3: Core Mathematical Foundations
- Part 2: Architecture & Building Blocks
- Chapter 4: Neural Networks Fundamentals
- Chapter 5: The Transformer Architecture
- Chapter 6: Attention Mechanisms
- Chapter 7: Multi-Dimensional Vectors & Embeddings
- Part 3: Advanced Concepts & Techniques
- Chapter 8: Training and Fine-tuning
- Chapter 9: Prompt Engineering & RAG
- Chapter 10: Scaling and Optimization
- Part 4: Industry Applications & Automation
- Chapter 11: LLM Use Cases Across Industries
- Chapter 12: Building LLM-Powered AI Systems
- Chapter 13: Best Practices & Deployment
- Conclusion & Career Path
PART 1: FOUNDATIONS OF LARGE LANGUAGE MODELS
Introduction & Executive Summary
Welcome to your comprehensive guide on Large Language Models (LLMs)—transformative AI technologies reshaping how organizations approach automation, decision-making, and human-computer interaction. This document is designed specifically for new AI engineers joining global MNC tech companies, providing both theoretical foundations and practical industry applications[1].
This comprehensive guide covers:
Foundations: Understanding what LLMs are, their mathematical underpinnings, and their evolution
Architecture: Deep dive into transformer architecture, attention mechanisms, and neural network design
Advanced Techniques: Training methods, fine-tuning approaches, prompt engineering, and RAG (Retrieval-Augmented Generation)
Industry Applications: Real-world use cases across finance, healthcare, marketing, automation, and tech sectors
Practical Implementation: Building production-ready LLM systems for enterprise environments
According to recent industry research, more than 40% of all U.S. work activity can be augmented or automated using LLMs[2]. Major organizations are already deploying LLM-powered solutions:
- Finance: Fraud detection, risk management, algorithmic trading
- Healthcare: Medical diagnosis, drug discovery, patient interaction
- Manufacturing: Process automation, quality control, predictive maintenance
- Tech & IT: Code generation, documentation, software testing, workflow automation
This guide is structured progressively—starting with fundamental concepts and advancing to enterprise-scale implementation patterns. Whether you’re focusing on development, research, or deployment, you’ll find actionable insights aligned with industry best practices[3].
Chapter 1: What are Large Language Models?
A Large Language Model (LLM) is a type of artificial neural network trained on vast amounts of text data to understand, generate, and manipulate human language. LLMs represent one of the most significant breakthroughs in artificial intelligence, combining deep learning with natural language processing (NLP) to perform tasks that previously required human intelligence[1].
Scale: Measured in parameters (billions to trillions)
- GPT-3: 175 billion parameters
- GPT-4: Estimated 1+ trillion parameters
- LLaMA 3: 70 billion parameters
- Gemini: Multi-billion parameter models
Versatility: Can perform multiple tasks without task-specific training
- Text completion and generation
- Question answering
- Translation and summarization
- Code generation and debugging
- Reasoning and analysis
Context Awareness: Understanding relationships between words across long sequences
- Managing context windows (2K to 100K+ tokens)
- Tracking conversation history
- Maintaining coherence in long-form generation
Emergent Abilities: Advanced capabilities arising from scale[2]
- Few-shot learning (learning from examples)
- Zero-shot learning (performing unseen tasks)
- In-context learning (adapting based on prompts)
- Chain-of-thought reasoning (step-by-step problem solving)
LLMs demonstrate core competencies that serve as building blocks for sophisticated AI systems:
- Text Completion: Generating coherent continuations of partial text
- Text Generation: Creating original content from prompts
- Question Answering: Providing accurate responses with reasoning
- Summarization: Condensing information while preserving meaning
- Translation: Converting between languages preserving semantics
- Relation Extraction: Identifying connections between entities
- Sentiment Analysis: Understanding emotional tone and perspective
- Data Extraction: Pulling specific information from unstructured text
- Classification: Categorizing text into predefined classes
- Reasoning: Performing logical inference and mathematical operations

How LLMs Work: High-Level Overview
At their core, LLMs operate through a sophisticated process:
1. Tokenization: Breaking text into manageable pieces (tokens)
2. Embedding: Converting tokens to high-dimensional vectors
3. Processing: Running through multiple transformer layers
4. Attention: Calculating which parts of input are relevant
5. Generation: Producing next token probability distribution
6. Decoding: Sampling output token and repeating process
1. Automation at Scale
- Reducing manual effort in document processing
- Automating customer interactions
- Enabling 24/7 support systems
2. Knowledge Accessibility
- Democratizing expertise
- Making complex information understandable
- Providing instant contextual learning
3. Creative and Analytical Capabilities
- Generating novel content
- Analyzing large datasets quickly
- Supporting decision-making with reasoning
4. Cost Efficiency
- Reducing need for domain experts on routine tasks
- Accelerating software development
- Improving operational efficiency
Chapter 2: Historical Context and Evolution
The path to today’s LLMs represents decades of advancement in artificial intelligence and machine learning:
Pre-2010: Foundation Building
- Introduction of neural networks and backpropagation
- Development of recurrent neural networks (RNNs)
- Early work in NLP with statistical methods
2010-2016: Deep Learning Revolution
- Convolutional neural networks for computer vision
- Long Short-Term Memory (LSTM) networks
- Word2Vec and embedding techniques
2017: The Transformer Moment
- Publication of “Attention Is All You Need” paper
- Introduction of transformer architecture
- Revolutionary parallel processing capability
2018-2019: Scaling Era Begins
- BERT introduced by Google (110 million parameters)
- GPT-2 released (1.5 billion parameters)
- Industry recognition of scaling benefits
2020-2021: GPT-3 and Explosion of Scale
- GPT-3 released with 175 billion parameters
- Few-shot and zero-shot learning demonstrated
- Industry investment explodes
2022-2023: Specialized and Optimized Models
- LLaMA (7B-65B parameters) released
- ChatGPT introduces consumer-facing LLMs
- Fine-tuning techniques (LoRA, adapters) developed
- RAG and prompt engineering mature
2024-2025: Advanced Architectures and Efficiency
- Mixture of Experts (MoE) models emerge
- Mamba-based state-space models as transformer alternatives
- Hybrid architectures combining multiple approaches
- Edge deployment and quantization advances[1]
Scaling Laws and Emergent Capabilities
A critical discovery in LLM development is the existence of scaling laws—predictable patterns describing how model performance improves with increased parameters, data, and compute[2]:
Where N = parameters, D = data, C = compute, and α, β, γ are scaling exponents.
Key Insights:
- Performance improves predictably with scale
- Larger models require more data efficiently
- Compute allocation significantly affects outcomes
- Benefits continue up to trillion-parameter range
Emergent Abilities: Capabilities that appear suddenly at specific scales[3]
- Chain-of-thought reasoning (larger models reason better)
- Multi-task learning (single model handles diverse tasks)
- In-context learning (learning from examples in prompts)
- Instruction following (understanding complex directives)
| Architecture | Key Features | Era | Parameters |
| RNN/LSTM | Sequential processing, early attention | 2000s-2010s | Millions |
| Transformer (Original) | Self-attention, parallel processing | 2017 | Billions |
| GPT Series | Decoder-only, autoregressive generation | 2018-2024 | 7B-1T+ |
| BERT-style | Encoder-focus, bidirectional context | 2018-2021 | 100M-1B |
| T5 | Encoder-decoder unified architecture | 2019-2024 | 60M-11B |
| Mamba | State-space models, linear complexity | 2024-2025 | Billions |
| Hybrid Models | Combining attention with SSM | 2024-2025 | Billions |
Chapter 3: Core Mathematical Foundations
Understanding LLMs requires mathematical foundations in linear algebra, calculus, and probability. This chapter provides essential concepts for engineers implementing and deploying LLMs.
Vectors: Ordered lists of numbers representing data points
Vector Operations:
- Dot Product:
(measures similarity)
- Norm:
(measures magnitude)
- Cosine Similarity:
(angle between vectors)
Matrices: Two-dimensional arrays of numbers
Matrix Operations:
- Matrix Multiplication: Critical for neural network forward pass
- Transpose: Flipping rows and columns (
)
- Inverse: Finding
such that
- Eigenvalues and Eigenvectors: Fundamental properties of matrices
Tensor: Multi-dimensional generalization of matrices
In LLMs, tensors represent:
- Batches of sequences: (batch_size, sequence_length, embedding_dim)
- Attention weights: (batch_size, num_heads, seq_len, seq_len)
- Model parameters: Multiple dimensions depending on layer type
LLMs are trained using gradient-based optimization, requiring understanding of derivatives and backpropagation:
Derivatives: Rate of change of a function
Partial Derivatives: Derivatives with respect to one variable among many
Chain Rule: Essential for backpropagation in neural networks
Gradient: Vector of all partial derivatives pointing toward steepest increase
Gradient Descent: Optimization algorithm moving parameters in direction of negative gradient
Where is learning rate and
is loss function.
LLMs fundamentally work with probability distributions over possible outputs:
Probability Distribution: Assignment of probability to each possible outcome
Conditional Probability: Probability of event given context
Softmax Function: Converts unnormalized scores to probabilities
Cross-Entropy Loss: Measures difference between predicted and actual probability distributions
Where is true label and
is predicted probability.
Entropy: Measure of uncertainty in probability distribution
High entropy = high uncertainty; Low entropy = high confidence.
PART 2: ARCHITECTURE & BUILDING BLOCKS
Chapter 4: Neural Networks Fundamentals
A neural network is a computational model inspired by biological neurons, organized into layers of interconnected nodes. Neural networks learn by adjusting connection strengths (weights) based on training data, enabling them to recognize patterns and make predictions[1].
Building Blocks of Neural Networks
Neurons (Nodes): Computational units that process information
Where:
= weights (learned parameters)
= input vector
= bias (learned parameter)
- activation = non-linear function
Layers: Groups of neurons processing data together
- Input Layer: Receives raw data (tokens, pixel values, etc.)
- Hidden Layers: Learn representations and patterns from data
- Output Layer: Produces final predictions (next token probabilities)
Weights and Biases: Learnable parameters adjusted during training
For a neural network layer:
Non-linear functions introducing complexity to neural networks, enabling learning of non-linear patterns:
ReLU (Rectified Linear Unit): Most common in modern networks
Advantages: Computationally efficient, prevents vanishing gradient problem
Sigmoid: Maps inputs to (0, 1) probability range
Usage: Often in output layers for binary classification
Tanh: Maps inputs to (-1, 1) range, centered around zero
Usage: Hidden layers, RNNs, provides stronger gradients than sigmoid
GELU (Gaussian Error Linear Unit): Preferred in transformers
Where is cumulative distribution function of standard normal distribution.
Forward Pass: Computing Network Output
The forward pass propagates input through layers to produce output:
Example: Three-layer network
Each layer transforms input to new representation, with later layers capturing more abstract patterns.
Backpropagation: Learning from Mistakes
Backpropagation efficiently computes gradients of loss with respect to all parameters using chain rule:
Training Process:
- Forward pass: Compute predictions
- Calculate loss: Measure prediction error
- Backward pass: Compute gradients
- Update parameters: Move in direction of negative gradient
- Repeat: Multiple iterations on dataset
Challenges and Solutions in Deep Networks
Vanishing Gradient Problem: Gradients become too small in deep networks
- Symptoms: Early layers stop learning
- Solution: ReLU activation, residual connections, batch normalization
Exploding Gradient Problem: Gradients become too large
- Solution: Gradient clipping, proper weight initialization
Overfitting: Model memorizes training data instead of learning patterns
- Solution: Regularization, dropout, early stopping, validation monitoring
Chapter 5: The Transformer Architecture
Revolutionary Innovation: From RNNs to Transformers
Traditional sequence models (RNNs, LSTMs) process sequences sequentially:
This sequential dependency creates computational bottlenecks and difficulty in capturing long-range dependencies.
The Transformer Breakthrough (2017): Process entire sequences in parallel using self-attention
Transformer Architecture Overview
The transformer consists of encoder and decoder stacks, each with identical layers:
Encoder:
- Input: Sequence of tokens
- Output: Context-rich representations
- Process: Self-attention + Feed-forward
Decoder:
- Input: Target tokens (during training), previously generated tokens (inference)
- Output: Probability distribution over vocabulary
- Process: Self-attention + Cross-attention + Feed-forward
Flow Diagram:
Input Tokens
↓
Tokenization
↓
Input Embedding + Positional Encoding
↓
┌─────────────────────────────────┐
│ Encoder Stack (N layers) │
│ ├─ Multi-Head Self-Attention │
│ ├─ Feed-Forward Networks │
│ └─ Layer Normalization │
└─────────────────────────────────┘
↓
┌─────────────────────────────────┐
│ Decoder Stack (N layers) │
│ ├─ Masked Self-Attention │
│ ├─ Cross-Attention │
│ ├─ Feed-Forward Networks │
│ └─ Layer Normalization │
└─────────────────────────────────┘
↓
Output Projection
↓
Softmax
↓
Next Token Probabilities
1. Embedding Layer
Converts discrete tokens into continuous vectors:
Where V is vocabulary size and is embedding dimension (typically 768-12288).
2. Positional Encoding
Adds information about position of tokens in sequence:
3. Multi-Head Self-Attention
Core mechanism enabling context understanding (detailed in Chapter 6).
4. Feed-Forward Networks
Position-wise fully connected networks applied to each position:
Typically:
5. Layer Normalization
Stabilizes training by normalizing layer outputs:
6. Residual Connections
Enable deep networks by allowing gradients to flow directly:
Encoder-Only Models (BERT, RoBERTa):
- Use encoder stack with bidirectional attention
- Suited for understanding/classification tasks
- Training: Masked language modeling, next sentence prediction
Decoder-Only Models (GPT, LLaMA):
- Use decoder stack with causal masking
- Suited for text generation tasks
- More parameters can be dedicated to generation
Encoder-Decoder Models (T5, BART):
- Use both encoder and decoder stacks
- Suited for seq2seq tasks (translation, summarization)
- Maximum flexibility for various tasks
Modern Transformer Optimizations
Grouped-Query Attention (GQA)[1]:
- Reduces memory usage and latency in inference
- Multiple query heads share key and value heads
- Performance with significant efficiency gains
Multi-Head Latent Attention (MLA)[1]:
- Projects attention to lower-dimensional latent space
- Reduces computation while maintaining performance
- Used in advanced models
Sliding Window Attention[1]:
- Attention only to recent tokens (local context)
- Reduces complexity from O(n²) to O(n)
- Maintains performance for tasks not requiring long-range attention
Mixture of Experts (MoE)[1]:
- Sparse activation: only subset of parameters active per input
- Massive parameter count with reasonable compute
- Models like DeepSeek V3 use sophisticated MoE
- Example: 671B total parameters, 37B active per token
Chapter 6: Attention Mechanisms
Attention is a mechanism allowing models to focus on relevant parts of input when processing each element. Without attention, all input elements contribute equally to output. Attention weights these contributions dynamically[1].
Motivation: In language, words have different relevance depending on context. “Bank” in “river bank” differs from “bank” in “bank account.”
Self-Attention: The Foundation
Self-attention enables each element to relate to all other elements in sequence, computing relevance scores[2]:
Three learnable weight matrices:
Step 1: Project to Query, Key, Value
For each input embedding :
Step 2: Compute Attention Scores
Query interacts with all keys:
Step 3: Normalize with Softmax
The scaling prevents scores from becoming too large.
Step 4: Weight and Aggregate Values
Scaled Dot-Product Attention Formula
Combining all steps in matrix form:
Where:
= Query matrix (seq_len × d_k)
= Key matrix (seq_len × d_k)
= Value matrix (seq_len × d_v)
- Output = (seq_len × d_v)
Running attention in parallel with different representation subspaces:
Multiple representation spaces:
Concatenate all heads:
Where h is number of heads (typically 8-12 or more).
Advantages:
- Model relationships in different subspaces
- Distribute information across heads
- More expressive attention patterns
- Parallel computation
Attention Visualization: Example
Consider sentence: “The quick brown fox jumps over the lazy dog”
When processing “fox”, attention weights might focus:
- 30% on “quick” (describes fox)
- 25% on “brown” (describes fox)
- 20% on “dog” (will be jumped over)
- 15% on “fox” (self-attention)
- 10% on other words
This allows “fox” representation to incorporate relevant context.
Attention in Encoder vs Decoder
Encoder Self-Attention:
- Each position attends to all positions (including itself)
- Bidirectional context understanding
- Fully visible attention mask
Decoder Self-Attention:
- Each position attends only to earlier positions (causal)
- Prevents seeing future tokens during generation
- Triangular attention mask
Encoder-Decoder Cross-Attention:
- Decoder queries attend to encoder outputs
- Decoder can focus on relevant input for generation
- Enables seq2seq tasks (translation, summarization)
Long-Range Dependencies: Directly connects distant tokens
- Traditional RNNs struggle: gradient vanishes over distance
- Attention: direct path regardless of distance
Parallelization: Compute all positions simultaneously
- RNNs: sequential computation (slow)
- Attention: parallel computation (fast)
Interpretability: Attention weights show what model focuses on
- Explainability in decision-making
- Debugging and understanding behavior
Chapter 7: Multi-Dimensional Vectors and Embeddings
Understanding Vector Representations
Embeddings convert discrete symbols (words, tokens) into continuous vectors that capture semantic and syntactic properties. Semantically similar words have similar embeddings[1].
One-Dimensional: Single number (limited information)
Two-Dimensional: Pair of numbers (visualizable)
Enables 2D visualization where distance relates to semantic similarity:
happy
↑
|
|
sad ← → → joy
|
↓
angry
High-Dimensional Vectors: Typically 768 to 12,288 dimensions in LLMs
Semantic Relationships Encoded as Vector Operations:
Cosine Similarity Measures Semantic Relatedness:
- 1.0: Identical direction (same meaning)
- 0.0: Orthogonal (unrelated)
- -1.0: Opposite direction (opposite meaning)
Tokenization: Breaking text into tokens
“Hello, how are you?”
↓
Tokens: [“Hello”, “,”, “how”, “are”, “you”, “?”]
↓
Token IDs: [1023, 11, 2145, 678, 1984, 27]
Embedding Matrix: Maps token IDs to vectors
Where V = vocabulary size, = embedding dimension.
Embedding Lookup: Retrieving vector for token
Since transformers process sequences in parallel, position information requires explicit encoding.
Sinusoidal Position Encoding (Original Transformer):
Properties:
- Different frequencies for different dimensions
- Periodic patterns enable model to learn relative positions
- Generalizes to sequences longer than training sequences
Learned Position Embeddings:
- Position-specific learnable vectors
- More parameter-intensive
- May struggle generalizing to longer sequences
Rotary Position Embeddings (RoPE)[1]:
- Rotate embedding vectors based on position
- Better long-range dependency modeling
- Used in LLaMA, GPT-NeoX
Token embeddings are static, but LLMs produce contextual embeddings varying based on context:
Word: “bank”
Sentence 1: “I went to the river bank” → embedding₁
Sentence 2: “I went to the bank to deposit money” → embedding₂
embedding₁ ≠ embedding₂
After processing through transformer layers, same token produces different embeddings based on context, capturing meaning.
2D Projection of High-Dimensional Embeddings (using t-SNE or UMAP):
positive
↑
│ wonderful ●
│ amazing ●
│ great ●
│
───────┼──────────── → intensity
│
│ terrible ●
│ awful ●
│ bad ●
↓
negative
Similar words cluster together in embedding space.
Embeddings enable semantic operations:
Addition (combining concepts):
Interpolation (blending concepts):
Analogy (solving relationships):
Trade-offs in Embedding Dimension:
| Dimension | Pros | Cons |
| 256 | Fast, memory efficient | Limited expressiveness |
| 768 | Standard BERT-size | Medium compute |
| 1536 | GPT-3, diverse models | Higher compute |
| 4096+ | Very large models | Significant compute, memory |
Model size typically scales with embedding dimension and transformer layers.
PART 3: ADVANCED CONCEPTS & TECHNIQUES
Chapter 8: Training and Fine-tuning
Pre-training: Building Foundation Knowledge
Objective: Learn general language patterns and world knowledge from vast unlabeled data.
Pre-training Process:
- Data Collection: Terabytes of text from diverse sources
- Tokenization: Convert text to tokens
- Preprocessing: Clean, filter, deduplicate data
- Training: Optimize language modeling objective
Causal Language Modeling (GPT-style):
Predict next token given previous tokens:
Masked Language Modeling (BERT-style):
Predict masked tokens given surrounding context:
Objective Function: Cross-entropy loss
Key Considerations:
Compute: Measured in FLOPs (floating-point operations)
- Transformer compute dominated by attention: O(n²) where n = sequence length
- Model size, batch size, sequence length, training steps all increase compute
Data: Quality and quantity critical[1]
- Pre-training typically uses 500B-5T tokens
- Data diversity improves generalization
- Data quality more important than quantity (diminishing returns)
Infrastructure:
- GPU/TPU clusters with high-speed interconnects
- Model parallelism: Distribute model across multiple devices
- Data parallelism: Distribute batch across multiple devices
- Pipeline parallelism: Stages of network on different devices
Stochastic Gradient Descent (SGD):
Simple but can oscillate significantly.
Adam Optimizer (Industry Standard):
$$
m_t = \beta_1 m_{t-1} + (1-\beta_1) \nabla L(\theta_t)$$
$$
v_t = \beta_2 v_{t-1} + (1-\beta_2) [\nabla L(\theta_t)]^2$$
Adaptive learning rates per parameter based on gradient history.
Fine-tuning: Adapting to Specific Tasks
Goal: Customize pre-trained model for specific domain or task.
Fine-tuning Approaches:
1. Full Fine-tuning
- Update all model parameters
- Best performance but computationally expensive
- Requires significant labeled data
- Risk of catastrophic forgetting
2. Parameter-Efficient Fine-tuning (LoRA, Adapters)
LoRA (Low-Rank Adaptation)[1]:
- Add trainable low-rank matrices to existing weights
- Freeze base model weights
- 10,000× parameter reduction vs full fine-tuning
- Minimal performance loss
Where B and A are low-rank matrices learned during fine-tuning.
Adapter Modules:
- Small trainable bottleneck layers
- Insert between transformer layers
- 0.5-2% additional parameters per task
3. Instruction Fine-tuning
Teach model to follow instructions by fine-tuning on:
- Input: Instruction (e.g., “Translate to French”)
- Output: Desired response
Dramatically improves instruction following across tasks.
4. Reinforcement Learning from Human Feedback (RLHF)[1]
Pre-trained Model
↓
Instruction Fine-tuning (SFT)
↓
Reward Modeling (Learn to evaluate quality)
↓
RL Training (Optimize using reward model)
↓
Production Model
Aligns model outputs with human preferences.
Step 1: Data Preparation
- Collect domain-specific labeled data
- Split into train/validation/test
- Format consistently with pre-training format
Step 2: Hyperparameter Selection
| Parameter | Full Fine-tune | LoRA | PEFT |
| Learning Rate | 1e-5 to 5e-5 | 1e-4 to 5e-4 | 1e-4 to 1e-3 |
| Batch Size | 8-32 | 16-64 | 32-128 |
| Epochs | 2-5 | 3-10 | 5-20 |
| Warmup Steps | 5-10% | 5% | 2-5% |
Step 3: Training
- Monitor validation loss
- Early stopping when validation plateaus
- Save best checkpoint
Step 4: Evaluation
- Task-specific metrics
- Human evaluation
- Comparison to baseline
Challenge: Model trained on general text may not understand domain-specific language.
Solution: Continued pre-training on domain data
- Further language modeling on domain corpus
- Followed by fine-tuning on task data
- Preserves general knowledge while adding domain expertise
Example: Financial LLM
- Pre-train on general English
- Continue pre-training on financial documents
- Fine-tune on customer service queries
- Result: Model understands finance AND customer service
Chapter 9: Prompt Engineering and RAG
Prompt Engineering: Guiding LLM Behavior
Prompt engineering is the art and science of crafting inputs to elicit desired outputs from LLMs[1].
1. Clarity and Specificity
❌ Poor: “What do you know about AI?”
✅ Better: “Explain how transformer architectures enable parallel
processing in LLMs, using mathematical notation where appropriate.”
2. Structure and Format
Task: Classify customer feedback
Input Text: “The service was slow but the staff was friendly”
Classify as: Positive/Negative/Neutral
Confidence (0-1):
3. Few-Shot Examples
Providing examples dramatically improves performance:
Sentiment Classification Examples:
- “Great product!” → Positive
- “Terrible experience” → Negative
- “It’s okay” → Neutral
Now classify: “Amazing quality, fast shipping” →
4. Role Definition
You are an expert financial analyst with 20 years of experience.
Your task is to analyze this quarterly earnings report…
Chain-of-Thought (CoT) Prompting[1]:
Asking model to show reasoning step-by-step significantly improves accuracy, especially on complex tasks:
Q: If there are 3 cars in the lot and 2 more cars arrive,
how many cars are in the lot?
❌ Without CoT: “5 cars”
✅ With CoT: “Let me think through this step by step:
- Initially: 3 cars
- Arriving: 2 cars
- Total: 3 + 2 = 5 cars”
Tree-of-Thought Prompting:
Explores multiple reasoning paths and selects best:
Problem: Arrange A, B, C such that A < B > C
Path 1: Try A=1, B=3, C=2 → Valid
Path 2: Try A=2, B=1, C=3 → Invalid (B not max)
Path 3: Try A=1, B=2, C=0 → Valid
Best solution: A=1, B=3, C=2
Meta-Prompting:
Using LLM to optimize prompts:
You are a prompt optimization expert.
Improve this prompt to get better results: [original prompt]
Retrieval-Augmented Generation (RAG)
Problem: LLMs have knowledge cutoff; can’t access real-time or proprietary data.
Solution: RAG combines retrieval with generation[1]
RAG Architecture:
User Query
↓
Retrieve Relevant Documents from Knowledge Base
↓
Combine Query + Retrieved Context
↓
Pass to LLM as Input
↓
LLM Generates Response with Grounding
↓
Output with Citation to Source Documents
1. Document Processing
- Split documents into chunks (sentences, paragraphs)
- Embed chunks into vectors
- Store in vector database for fast retrieval
2. Retrieval
- Convert query to embedding
- Find most similar document embeddings (cosine similarity)
- Return top-K documents
3. Augmentation
- Insert retrieved documents into prompt context
- Instruct model to use retrieved information
- Reduce hallucination through grounding
4. Generation
- Model generates response informed by retrieved context
- Can cite source documents
- More accurate and trustworthy
RAG vs Fine-tuning vs Prompt Engineering
| Approach | Use Case | Pros | Cons | Latency |
| Prompt Engineering | Quick experiments, demos | Easy, no training | Limited, inconsistent | Low |
| RAG | Integrate external knowledge, real-time data | Dynamic, fresh data | Retrieval errors | Medium |
| Fine-tuning | Domain-specific behavior, style, format | Consistent, reliable | Expensive, static | Low |
When to Combine:
- Use prompt engineering + RAG for dynamic retrieval
- Use fine-tuning + RAG for domain consistency + fresh data
- Use fine-tuning to improve in-context learning
Hybrid Retrieval[1]:
Combining keyword search with semantic similarity:
Re-ranking:
Initial retrieval returns broad results; re-ranking model scores relevance:
Retrieved (50 documents) → Re-ranker → Top 5 Most Relevant
Query Expansion:
Generate related queries to retrieve more relevant information:
Original: “What is neural architecture search?”
Expanded: [
“neural architecture search”,
“NAS algorithms”,
“automated machine learning”,
“architecture optimization”
]
Chapter 10: Scaling and Optimization
Modern LLMs push boundaries in multiple dimensions simultaneously[1]:
Model Scaling:
- Parameters: From millions (2010s) to trillions (2020s)
- Layers: From 6-12 to 100+
- Compute requirements grow non-linearly
Data Scaling:
- Training tokens: From billions to trillions
- Diverse sources: Common crawl, books, academic papers, code
- Data quality increasingly important as quantity reaches limits
Compute Scaling:
- GPU/TPU clusters with thousands of units
- High-speed interconnects between devices
- Distributed training frameworks (Megatron-LM, etc.)
Empirical observations show predictable scaling relationships[1]:
Chinchilla Scaling Laws:
Optimal compute allocation:
- 50% to model size (parameters)
- 50% to data size (training tokens)
- Training tokens ≈ 20 × Parameters
Where N=parameters, D=data, A,B,E=constants, α≈0.07, β≈0.21
Model Compression
Quantization: Reduce precision of weights/activations
- FP32 (32-bit float) → FP16 (16-bit) → INT8 (8-bit) → INT4 (4-bit)
- Reduces memory by 4-8×
- Enables running larger models on smaller hardware
INT4 Quantization Example:
- FP32: 175B parameters × 4 bytes = 700 GB
- INT4: 175B parameters × 1 byte = 175 GB (4× reduction)
Pruning: Remove less important weights/neurons
- Structured pruning: Remove entire heads or layers
- Unstructured pruning: Remove individual weights
- Trade accuracy for speed (typically 10-30% degradation)
Knowledge Distillation: Train smaller model to mimic large model
- Teacher model: Large, high accuracy
- Student model: Small, fast
- Student trained to match teacher outputs
Mixture of Experts (MoE)[1]
Sparse activation: Only subset of parameters active per forward pass
Architecture:
Input
↓
Router Network (determines which expert to use)
↓
Expert 1 (processes subset of data)
Expert 2 (processes subset of data)
…
Expert N (processes subset of data)
↓
Combine outputs
↓
Output
Benefits:
- 10-100× parameters with modest compute increase
- Different experts specialize in different domains/tasks
- Can balance compute across experts
Example: DeepSeek V3
- 671B total parameters
- 37B active per token
- ~18× parameter efficiency
Inference Challenges:
- Autoregressive generation: Slow (generate one token at a time)
- Memory: KV cache grows with sequence length
- Latency: Real-time applications require fast responses
Optimization Techniques:
KV-Cache Quantization:
- Store key-value tensors in lower precision
- Reduces memory bandwidth bottleneck
- Minimal impact on accuracy
Paged Attention:
- Allocate KV cache in pages like OS memory paging
- Reduce memory fragmentation
- Reuse cache across batch items
Grouped-Query Attention (GQA)[1]:
- Share key/value heads across query heads
- Reduce KV cache by 8-10×
- Minimal accuracy loss
Prefix Caching:
- Reuse computed KV cache from shared prefixes
- Important for retrieval-augmented applications
- Speeds up repeated queries
Specialized Hardware:
GPU (NVIDIA A100/H100):
- General-purpose, widely available
- Good for training and inference
- High power consumption
TPU (Google Tensor Processing Units):
- Specialized for tensor operations
- Excellent training efficiency
- Limited availability
Custom Silicon (AWS Trainium, Cerebras):
- Optimized for specific workloads
- Lower power, higher efficiency
- Emerging trend
Distributed Training Strategies
Data Parallelism:
- Split batch across multiple GPUs
- Each GPU processes subset of batch
- Gradients averaged across GPUs
Model Parallelism:
- Split model across multiple GPUs
- Each layer or layer group on different GPU
- Forward and backward passes pipeline through devices
Pipeline Parallelism:
- Divide model into stages
- Different stages on different GPUs
- Process multiple batches simultaneously
FSDP (Fully Sharded Data Parallel):
- Each GPU owns subset of model parameters
- Gradients, optimizer states also distributed
- Communication optimized for efficient scaling
PART 4: INDUSTRY APPLICATIONS & AUTOMATION
Chapter 11: LLM Use Cases Across Industries
Fraud Detection and Risk Management[1]
LLMs analyze transaction patterns, identifying anomalies in real-time:
- Transactions flagged within milliseconds
- Context from customer history and market conditions
- Reduces false positives vs rule-based systems
- Compliance: Automatic explanation generation for audits
Example: Bank processes 10M transactions daily
- Traditional rule-based: 5% false positive rate
- LLM-augmented: 0.2% false positive rate
- Manual review time reduced 80%
Algorithmic Trading:
- Market sentiment from news, earnings calls, social media
- Real-time analysis of complex financial documents
- Position recommendations with risk assessment
- Backtesting strategies on historical data
Customer Service Automation[1]
- 24/7 support for account inquiries, transactions, financial advice
- Multi-turn conversations maintaining context
- Escalation to human agents for complex issues
- Natural language processing of customer intent
Medical Diagnosis Assistance[1]
- Analyze patient symptoms, medical history, test results
- Suggest diagnoses ranked by probability
- Recommend relevant diagnostic tests
- Cite supporting evidence from medical literature
Drug Discovery and Development:
- Analyze chemical compound properties
- Predict drug-protein interactions
- Generate new compound candidates
- Accelerate research from years to months
Example: Protein folding and simulation
- Process molecular biology data
- Generate protein structure hypotheses
- Simulate interactions computationally
- Result: Drug candidates in fraction of traditional time
Medical Documentation:
- Auto-generate clinical notes from doctor-patient conversations
- Extract relevant information from unstructured records
- Improve patient record quality and accessibility
- Reduce administrative burden on healthcare providers
Manufacturing and Supply Chain
Product Attribute Extraction (PAE)[1]
Walmart case study: Extract attributes from product catalogs
- Multi-modal processing (text + images from PDFs)
- Automated categorization and inventory management
- Improved customer shopping experience
- Result: Accurate product hierarchies across millions of SKUs
Supply Chain Risk Management[1]
Altana case study: Automated supply chain intelligence
- Tax classification: Automatically calculate tariffs and compliance
- Risk assessment: Identify supply chain vulnerabilities
- Compliance automation: Generate regulatory-required documentation
- Result: Reduced compliance risk, improved efficiency
Predictive Maintenance:
- Analyze sensor data from equipment
- Predict failures before they occur
- Schedule maintenance proactively
- Reduce costly downtime and failures
Content Generation[1]
- Personalized marketing messages for different segments
- Social media content automatically created and scheduled
- A/B testing copy variants at scale
- Multi-language campaigns simultaneously
Customer Insight Mining[1]
- Analyze customer feedback, reviews, social media
- Extract preferences and pain points
- Generate actionable business insights
- Improve product positioning
Personalized Recommendations:
- Analyze customer browsing, purchase history
- Generate personalized product/content recommendations
- Dynamic pricing based on demand prediction
- Increase conversion rates 15-30%
Code Generation and Debugging[1]
- Generate code from natural language specifications
- Identify and fix bugs in existing code
- Auto-generate documentation from code
- Accelerate software development by 30-40%
Example: Development workflow
- Engineer describes feature in plain English
- LLM generates implementation code
- LLM generates unit tests
- Tests validate code works
- Documentation auto-generated
- Result: 60% faster feature development
IT Operations Automation:
- Parse system logs and identify issues
- Suggest solutions for common problems
- Route issues to appropriate teams
- Reduce MTTR (Mean Time To Resolution)
Security Analysis:
- Analyze code for security vulnerabilities
- Generate exploit examples for testing
- Recommend fixes for identified issues
- Automated compliance checking
Intelligent Chatbots[1]
Multi-turn conversations maintaining context:
- Initial greeting and intent recognition
- Information retrieval from knowledge base
- Problem solving with clarifications
- Escalation to human agent if needed
Case Study: Octopus Energy
- AI-assisted emails for customer inquiries
- Higher CSAT (Customer Satisfaction) than human agents
- Superior speed and consistency
- Reduced documentation search burden
Workflow:
- Customer sends email
- LLM drafts response
- Human agent reviews/edits
- Sends to customer
- Result: 50% faster, better consistency
Chapter 12: Building LLM-Powered AI Systems
Pattern 1: Simple Prompt + Response
User Input → LLM → Output
Use case: Simple Q&A, content generation
- Fast to implement
- Limited by prompt engineering quality
- No external knowledge
Pattern 2: RAG (Retrieval-Augmented Generation)
User Query → Retrieve Documents → LLM + Context → Output
Use case: Domain-specific Q&A, documentation search
- Integrates external knowledge
- More accurate and traceable
- Requires document collection and embedding
Pattern 3: Agent with Tools
User Task → LLM → Tool Selection → Execute Tools → Result Integration → LLM → Response
Use case: Complex multi-step tasks
- Search the web
- Query databases
- Call APIs
- Perform calculations
Example Agent Flow:
Task: “What was the revenue growth of Tesla in Q3 2024?”
↓
Agent decides: Need current financial data
↓
Tool: Search_Financial_Data(“Tesla”, “Q3 2024”)
↓
Result: Revenue $25.2B, YoY growth 25%
↓
Agent generates response with data
↓
Output: “Tesla’s Q3 2024 revenue was $25.2B, growing 25% YoY”
Pattern 4: Multi-Agent System
Task Coordinator
↓
├─ Analyzer Agent (data analysis)
├─ Writer Agent (content generation)
├─ Reviewer Agent (quality check)
└─ Optimizer Agent (performance)
↓
Consensus Output
Use case: Complex workflows requiring multiple capabilities
- Breaking down tasks among specialized agents
- Iterative refinement of outputs
- Quality assurance
LLM Providers:
| Provider | Models | API Type | Enterprise |
| OpenAI | GPT-4, GPT-3.5 | API | Yes |
| Gemini, PaLM | API | Yes | |
| Anthropic | Claude | API | Yes |
| Meta | LLaMA 3 | Open source | Yes |
| Mistral | Mistral, Mixtral | Open source | Yes |
Framework Libraries:
- LangChain: Build chains and agents with LLMs
- LlamaIndex: Integrate LLMs with data
- AutoGPT: Autonomous agent framework
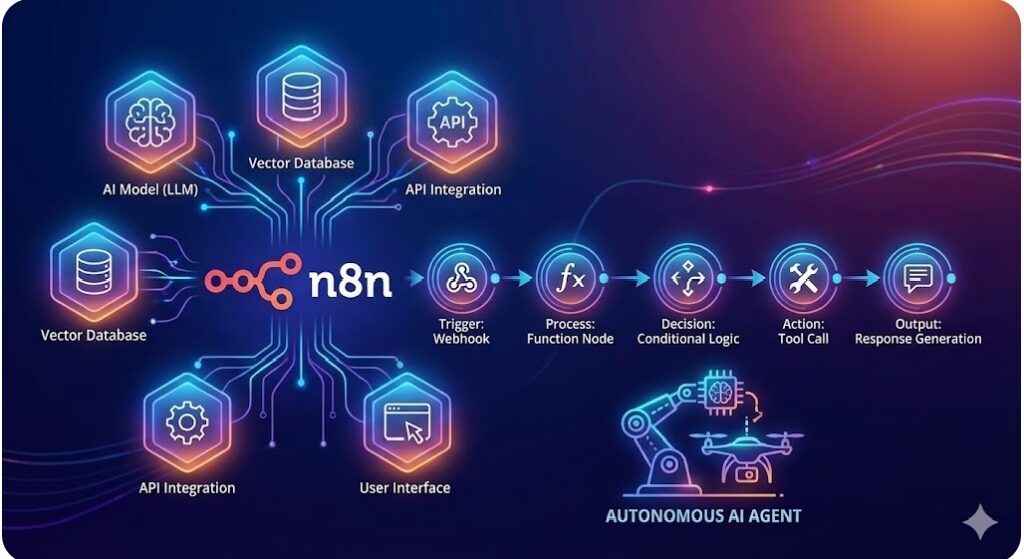
- n8n: Low-code workflow automation (n8n as mentioned in user preferences)
Vector Databases:
- Pinecone: Fully managed vector database
- Weaviate: Open-source vector database
- Milvus: Scalable vector database
- FAISS: Facebook’s vector search library
Deployment Platforms:
- Hugging Face: Model hosting and inference
- Replicate: Run models in cloud
- Together AI: Distributed model inference
- On-premises: vLLM, TensorRT-LLM for self-hosted
Building RAG System: Step-by-Step
Step 1: Document Collection
documents = collect_documents([
“pdfs/”,
“web_urls/”,
“databases/”
])
Step 2: Document Processing
chunks = split_documents(documents,
chunk_size=1000,
chunk_overlap=200)
chunks = preprocess(chunks)
Step 3: Embedding
embeddings = embed_model.encode(chunks)
Result: (num_chunks, embedding_dim)
Step 4: Store in Vector Database
vector_db.add_documents(
ids=chunk_ids,
documents=chunks,
embeddings=embeddings
)
Step 5: Query and Retrieve
query = “How does attention work?”
query_embedding = embed_model.encode(query)
results = vector_db.search(
query_embedding,
top_k=5 # Return 5 most relevant chunks
)
Step 6: Generate Response
context = “\n”.join([r[“document”] for r in results])
prompt = f”””
Based on the following context, answer the question:
Context:
{context}
Question: {query}
Answer:
“””
response = llm.generate(prompt)
Key Metrics:
Quality Metrics:
- Accuracy: Does output match expected?
- Relevance: Is output relevant to query?
- Factuality: Are facts accurate?
- Coherence: Is output well-structured?
Performance Metrics:
- Latency: Time from request to response
- Throughput: Requests per second
- Cost per request: Depends on token usage
- Success rate: % of requests returning valid response
User Metrics:
- User satisfaction: CSAT, NPS scores
- Engagement: Usage patterns
- Retention: Return user rate
- Error rates: Escalation rate to humans
Evaluation Framework:
Test Set
↓
├─ Input 1 → LLM Output 1
├─ Input 2 → LLM Output 2
└─ Input N → LLM Output N
↓
Evaluation Metrics
├─ LLM-as-Judge: Use another LLM to score quality
├─ Automated Metrics: ROUGE, BLEU, BERTScore
└─ Human Evaluation: Domain experts score samples
↓
Quality Score: Aggregate metric
Chapter 13: Best Practices and Deployment
Production Readiness Checklist
Before Deployment:
- [ ] Model selection and testing complete
- [ ] RAG knowledge base (if applicable) prepared
- [ ] Prompt templates thoroughly tested
- [ ] Error handling for edge cases
- [ ] Latency benchmarks meet requirements
- [ ] Cost analysis and budget planning
- [ ] Security review and access controls
- [ ] Privacy and data protection measures
- [ ] Monitoring and alerting setup
- [ ] Fallback strategies for failures
- [ ] User documentation prepared
- [ ] Support process established
Data Security:
- Encrypt data in transit (HTTPS/TLS)
- Encrypt data at rest
- Restrict API access with authentication
- Audit logs for compliance
Model Security:
- Use official model sources
- Verify model authenticity
- Regular security updates
- Monitor for adversarial attacks
Privacy Considerations:
- Minimize sensitive data in prompts
- Implement data retention policies
- Anonymize data when possible
- GDPR/CCPA compliance for user data
API Usage:
- Monitor token consumption
- Implement caching for repeated queries
- Batch requests when possible
- Use smaller models for simple tasks
Self-Hosted Models:
- One-time model download cost
- Inference costs depend on hardware
- More control over data
- Higher complexity
Cost Calculation Example:
API Model (GPT-4):
- Input: $0.03 per 1K tokens
- Output: $0.06 per 1K tokens
- Average request: 500 input + 200 output tokens
- Cost per request: $0.015 + $0.012 = $0.027
- 1M requests: $27,000
Self-Hosted Model (LLaMA 3 70B):
- GPU cost: $1/hour (A100 rental)
- Monthly: $720 (24/7 running)
- Amortized: $0.001 per request
- 1M requests: $1,000 amortized
- Break-even: 27,000 requests
Phased Rollout:
Phase 1: Beta (1% users)
↓ Validate performance
Phase 2: Broad Beta (10% users)
↓ Monitor quality at scale
Phase 3: General Availability (100% users)
↓ Full production deployment
Canary Deployment:
Route small percentage of traffic to new version:
90% → Old Version (proven, stable)
10% → New Version (testing)
↓ Monitor metrics
↓ If metrics good: increase percentage
↓ Eventually: 100% new version
A/B Testing:
Compare different approaches:
Group A: Model Version 1
Group B: Model Version 2
↓
Compare metrics:
- Quality scores
- User satisfaction
- Latency
- Cost
↓
Winner becomes default
Real-time Monitoring:
Metrics Collection → Aggregation → Alerting → Response
Key Metrics to Monitor:
- Request latency (p50, p95, p99)
- Success rate (% requests completing)
- Error rate by type
- Model performance degradation
- Cost per request trending
- User satisfaction (if collecting)
Alert Examples:
- Latency p99 > 5 seconds → Investigate
- Error rate > 1% → Page on-call engineer
- Cost/request > 20% above baseline → Review
- Model hallucination rate > 5% → Rollback
Handling Failures and Edge Cases
Failure Modes:
- Model Errors
- Solution: Fallback to previous version
- Solution: Escalate to human agent
- API Timeouts
- Solution: Implement retry logic with backoff
- Solution: Increase timeout gradually
- Solution: Queue requests if transient
- Rate Limiting
- Solution: Implement queue and backpressure
- Solution: Prioritize critical requests
- Solution: Scale infrastructure
- Hallucinations
- Solution: Fact-checking system
- Solution: Only use when confidence high
- Solution: Display confidence scores
Feedback Loops:
User Interaction
↓
Collect Feedback
↓
Identify Issues/Improvements
↓
Retrain/Fine-tune
↓
A/B Test Changes
↓
Deploy Best Performing Version
Techniques:
- Active Learning: Collect hard examples for labeling
- Online Learning: Update models continuously
- Periodic Retraining: Retrain on accumulated data
- User Feedback: Button for users to rate responses
Summary: Your LLM Knowledge Journey
You’ve now covered the complete spectrum of Large Language Models:
Part 1: Foundations
- What LLMs are and why they matter
- Historical evolution and scaling laws
- Mathematical foundations (linear algebra, calculus, probability)
Part 2: Architecture
- Neural network fundamentals
- Transformer architecture (encoder/decoder/hybrid)
- Attention mechanisms and their variants
- Vector embeddings and multi-dimensional representations
Part 3: Advanced Concepts
- Training, fine-tuning, and optimization techniques
- Prompt engineering and RAG systems
- Scaling strategies and efficiency improvements
- Modern optimizations (GQA, MoE, Mamba)
Part 4: Industry Applications
- Use cases across finance, healthcare, manufacturing, etc.
- Building production LLM systems
- Best practices and deployment strategies
1. LLMs are Transformative Technology
- 40%+ of work can be augmented or automated[1]
- Technology continues rapid advancement
- Early adopters gain competitive advantage
2. Understanding Architecture is Critical
- Transformers enable parallel processing and long-range dependencies
- Attention allows models to focus on relevant context
- Embeddings capture semantic meaning in numerical form
3. Practical Implementation Requires Multiple Skills
- Prompt engineering for task definition
- RAG for integrating external knowledge
- Fine-tuning for domain-specific optimization
- System design for production deployment
4. Efficiency Matters
- Scaling laws guide optimal compute allocation
- Quantization and pruning reduce inference cost
- MoE models achieve better efficiency
- Monitoring ensures cost-effective operations
5. Ethics and Responsibility
- LLMs can generate misleading information (hallucinations)
- Bias in training data affects outputs
- Security and privacy critical for enterprise use
- Transparency about AI capabilities and limitations essential
Level 1: AI Engineer (Your Current Role)
Responsibilities:
- Implement LLM-based solutions
- Integrate models into applications
- Prompt engineering and testing
- Monitor system performance
Skills to Develop:
- Python proficiency
- LLM APIs (OpenAI, Anthropic, Google)
- Vector databases and retrieval systems
- Deployment and monitoring
Timeline: 6-12 months
Responsibilities:
- Design LLM system architectures
- Fine-tune models for specific tasks
- Optimize performance and cost
- Mentor junior engineers
Skills to Develop:
- Advanced prompt engineering
- Fine-tuning and PEFT techniques
- System architecture design
- Cost optimization strategies
- Leadership and mentoring
Timeline: 2-3 years from Level 1
Level 3: AI/ML Solutions Architect
Responsibilities:
- Define enterprise AI strategies
- Design end-to-end AI solutions
- Evaluate and select appropriate models
- Provide technical guidance to teams
Skills to Develop:
- Deep understanding of model capabilities/limitations
- Enterprise system design
- Business acumen and ROI analysis
- Communication with stakeholders
- Industry knowledge (finance, healthcare, etc.)
Timeline: 3-5 years from Level 1
Level 4: AI/ML Research Scientist
Responsibilities:
- Advance state-of-the-art in specific areas
- Publish research papers
- Develop novel techniques
- Guide product roadmap
Skills to Develop:
- Advanced mathematics and theory
- Research methodology
- Paper writing and communication
- Expert-level understanding of specific domains
- Innovation mindset
Timeline: 5+ years from Level 1, often requires advanced degree
Official Documentation:
- Hugging Face: https://huggingface.co/learn
- OpenAI API: https://platform.openai.com/docs
- PyTorch: https://pytorch.org/tutorials
- Google Cloud AI: https://cloud.google.com/ai
Interactive Learning:
- DeepLearning.AI: Short courses on specific topics
- Coursera: Comprehensive ML/AI specializations
- FastAI: Practical deep learning for coders
- MLOps.community: Operational AI topics
Research and Papers:
- ArXiv.org: Latest research papers (search “large language models”)
- Papers with Code: Implementations accompanying research
- Medium and Towards Data Science: Technical blog posts
- Academic conferences: NeurIPS, ICML, ICLR
Hands-on Practice:
- Kaggle: Competitions and datasets
- LeetCode: Algorithm and coding practice
- Personal projects: Build systems for real problems
- Contribute to open source: GitHub projects
- n8n Community: Workflow automation practice (relevant to your interests)
Special Focus: LLMs in Tech & IT Automation
As an AI engineer in a global tech company, you likely focus on:
Using n8n and similar platforms with LLM nodes:
Trigger (Event)
↓
Extract Information
↓
Call LLM API
↓
Process Output
↓
Integrate with Other Systems
↓
Action/Update
Sophisticated multi-step automation:
User Request → Agent (decide next action)
↓ Decision
├─ Retrieve Information (RAG)
├─ Query Database
├─ Call External API
├─ Process Files
└─ Generate Report
↓
Aggregate Results
↓
Generate Response
Specific Use Cases for Tech Industry
1. Code Generation and Assistance
- GitHub Copilot and similar tools
- AI-assisted development workflow
- Bug detection and fixing
- Documentation generation
- Result: 30-40% faster development[1]
2. IT Operations
- Log analysis and anomaly detection
- Infrastructure as Code generation
- System troubleshooting automation
- Security vulnerability scanning
3. Knowledge Management
- Documentation search and retrieval
- Internal knowledge base Q&A
- Onboarding material generation
- Technical decision support
4. Data Pipeline Automation
- ETL workflow optimization
- Data quality monitoring
- Schema evolution suggestions
- Query optimization recommendations
The LLM field evolves rapidly—what’s cutting-edge today becomes standard next year. Your success depends on:
- Strong Fundamentals: Understanding core concepts deeply
- Practical Experience: Building real systems, not just studying
- Continuous Learning: Staying current with field advancement
- Problem-Solving Mindset: Applying LLMs creatively to business problems
- Responsibility: Using AI ethically and transparently
You’re entering AI at an exciting time. LLMs are transitioning from research curiosity to essential business infrastructure. Your work will directly impact how organizations operate and compete globally.
- Week 1-2: Implement a simple RAG system using Hugging Face and a vector DB
- Week 3-4: Fine-tune an open-source model (LLaMA) on domain-specific data
- Month 2: Build an LLM-powered automation workflow using n8n
- Month 3: Design and deploy a production system with monitoring
- Ongoing: Contribute to open-source LLM projects, stay current with research
You now possess the knowledge foundation to thrive in AI engineering. The rest is practical implementation, continuous learning, and creative problem-solving.
Welcome to the AI engineering community. You’re positioned at the forefront of technology transformation.

