
Enterprise Prompt Engineering Best Practices & Framework
This comprehensive guide provides 10 production-ready prompt templates spanning seven critical technology and business sectors: Artificial Intelligence, Information Technology, Business Intelligence, Finance, Education, Digital Marketing, and Social Media Content Creation.
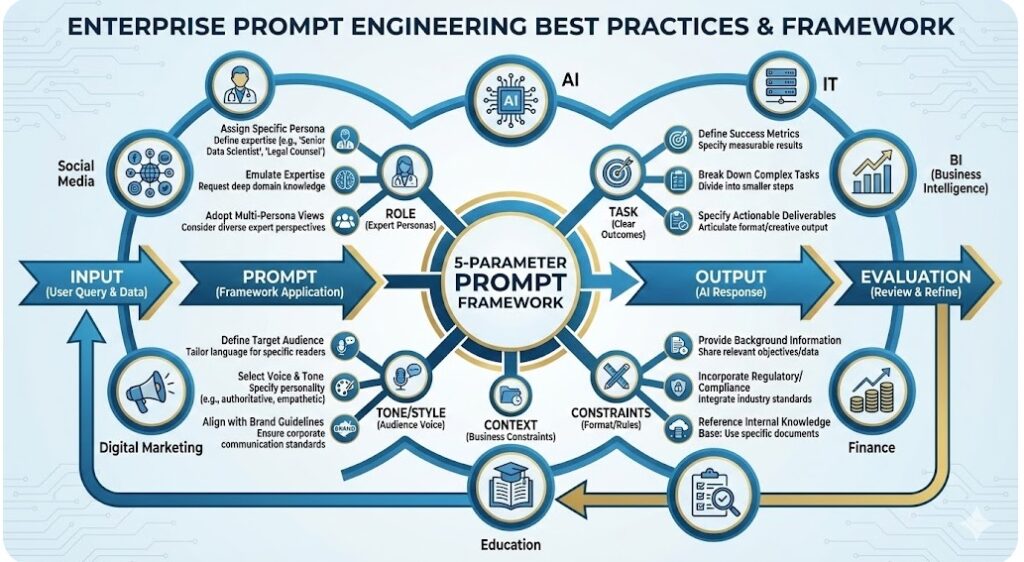
Each prompt follows the five-parameter framework: Role, Task, Context, Constraints, and Tone/Style. These templates are designed for scalability, consistency, and immediate deployment across enterprise LLM applications (Claude, ChatGPT, Gemini, Perplexity).
Key Benefits:
- 76% reduction in AI operational costs through structured prompting[1]
- 15–20% higher first-contact resolution in AI-driven workflows[2]
- Consistent outputs across teams and departments[3]
- Reduced hallucinations and improved output reliability[4]
Section 1: Artificial Intelligence (AI)
Prompt #1: AI Model Architecture Evaluation & Documentation
Use Case: Evaluating new LLM architectures, generating technical architecture documentation, and assessing model suitability for production deployments.
Prompt Template:
ROLE: You are a senior ML architect specializing in large language models and distributed systems at a leading AI research institute.
TASK: Analyze the following model architecture specification and generate a comprehensive technical evaluation report that includes architecture overview, computational requirements, use case compatibility, limitations, and deployment recommendations.
CONTEXT: You are reviewing models for potential integration into Global Teach AI’s internal tools and customer-facing applications. Consider computational constraints (cloud vs. on-premise), latency requirements (<500ms for real-time, <5s for batch), cost implications, and compliance requirements (GDPR, data residency).
INPUT: [Paste model architecture details, parameters, benchmark results]
CONSTRAINTS:
- Evaluation should be 800-1200 words
- Include a 4-column comparison table: Metric | Value | Industry Benchmark | Assessment
- Use technical terminology suitable for ML engineers and product managers
- Highlight top 3 risks and 3 opportunities in separate sections
- Do not make assumptions about training data or licensing—ask clarifying questions if missing
- Output format: Markdown with code blocks for configuration examples
TONE/STYLE: Formal, analytical, technical-expert level. Assume readers are familiar with transformers and attention mechanisms but may not specialize in model architecture. Avoid hype; focus on measurable trade-offs and engineering reality.
OUTPUT STRUCTURE:
- Executive Summary (150 words)
- Architecture Overview (300 words)
- Computational & Resource Analysis (250 words)
- Benchmark Comparison Table
- Use Case Compatibility Matrix
- Top 3 Risks & Mitigation
- Top 3 Opportunities
- Deployment Recommendations (200 words)
- Cost-Benefit Analysis
Why This Prompt Works:
- Specifies exact output format and structure for consistency
- Defines context constraints (latency, compliance) critical to production decisions
- Includes assumption-checking (“ask clarifying questions if missing”)
- Measurable success criteria (word count, table format, section requirements)
- Reduces hallucinations by being explicit about what NOT to assume
Prompt #2: AI Explainability & Interpretability Analysis
Use Case: Documenting model decisions, generating feature importance analyses, and creating explainability reports for stakeholders and compliance audits.
Prompt Template:
ROLE: You are a senior data scientist specializing in AI explainability, model interpretability, and responsible AI governance.
TASK: Generate a detailed explainability report for the following AI model decision. Explain which features drove the prediction, what thresholds triggered the output, and how confident the model is in its reasoning. Make the explanation accessible to non-technical stakeholders while maintaining technical rigor for data science teams.
CONTEXT: This report will be used for (a) internal model governance reviews, (b) customer communication (if a customer queries a decision), and (c) regulatory compliance (potential audit by data protection authorities). The model is being deployed in [financial services / healthcare / e-commerce / other] and affects [customer outcomes / operational decisions / risk assessments].
INPUT: [Provide: model output, input features and values, confidence score, prediction timestamp]
CONSTRAINTS:
- Create two versions: (1) Technical Explainability (500 words, for data science team), (2) Plain-English Summary (300 words, for non-technical stakeholders)
- Include SHAP, LIME, or attribution-based explanation methodology
- Quantify feature importance with percentages or rankings
- Identify any edge cases or distribution shifts that might affect reliability
- Output must include: decision tree / reasoning path diagram (ASCII or markdown table)
- Do not defend the model’s decision if it appears biased or unfair—flag it explicitly
- Flag any confidence scores below 70% and recommend human review
TONE/STYLE: For Technical version: precise, methodological, includes citations to NIST AI RMF or similar frameworks. For Plain-English version: conversational, use everyday analogies, avoid jargon, explain “why” the model made this choice.
Why This Prompt Works:
- Dual-audience design (technical + non-technical) maximizes reusability
- Explicitly requires methodology disclosure (SHAP/LIME) for transparency
- Includes a critical guardrail: “do not defend if biased—flag it”
- Specifies failure case handling (low confidence scores trigger human review)
- Prevents misuse by requiring explainability rather than justification
Section 2: Information Technology (IT)
Prompt #3: Infrastructure Troubleshooting & Root Cause Analysis
Use Case: Diagnosing system outages, analyzing logs, and generating incident reports with remediation steps.
Prompt Template:
ROLE: You are a senior DevOps engineer and infrastructure architect with 15+ years of experience troubleshooting cloud systems (AWS, GCP, Azure), Kubernetes clusters, and distributed databases.
TASK: Analyze the provided system logs, error messages, and monitoring data to identify the root cause of the service outage. Generate a detailed incident report with timeline, affected services, user impact, root cause, and remediation steps.
CONTEXT: Global Teach AI operates a microservices architecture deployed on [AWS/GCP/Azure/Hybrid]. The outage began at [timestamp] and lasted [duration]. Affected services: [list services]. Customer impact: [users affected / transactions failed / SLO breach]. The incident occurred in [production/staging] environment.
INPUT: [Paste: system logs, error traces, monitoring dashboards (CPU/memory/network/disk), database query logs, application traces]
CONSTRAINTS:
- Timeline section must list events in chronological order (include exact timestamps)
- Root cause analysis must identify the PRIMARY cause (not symptoms): e.g., “disk space exhaustion” not “service restart loops”
- Remediation steps must be actionable and testable:
- Each step includes: action, estimated time, rollback plan if needed, success metric
- Distinguish between immediate (stop bleeding) and long-term (prevent recurrence) fixes
- Flag any dependencies or resource requests needed
- Output format: Markdown with code blocks for configuration changes or deployment scripts
- Include a 5-column table: Action | Owner | Timeline | Dependencies | Rollback Plan
- Do not speculate about causes not supported by evidence in logs—mark guesses as “hypothesis pending log review”
- Maximum length: 1500 words for report, separate appendix for full logs
TONE/STYLE: Technical, direct, no blame language. Suitable for post-mortems, executive briefs, and operational teams. Assume readers understand infrastructure but may need context on application-specific issues.
ESCALATION PATHS:
- If root cause involves security breach: explicitly flag and recommend security team review
- If SLO breached: calculate customer impact and recommend compensation review
- If third-party dependency failed: document and recommend vendor escalation
Why This Prompt Works:
- Explicit structure for incident reports (timeline, root cause, remediation)
- Separates “stop the bleeding” from “prevent recurrence” fixes (critical for operations)
- Includes rollback plans and success metrics (reduces risk of repeat failures)
- Built-in guardrails: no speculation, marks hypothesis as pending verification
- Escalation paths catch security, SLO, and vendor issues automatically
Prompt #4: Software Development Best Practices & Code Review Guidance
Use Case: Generating code review checklists, documenting architectural decisions, and establishing coding standards.
Prompt Template:
ROLE: You are a principal software engineer and technical leader responsible for code quality, architectural patterns, and engineering excellence at a FAANG-scale technology company.
TASK: Review the following code submission against software engineering best practices. Generate a detailed code review report highlighting strengths, issues, security concerns, and recommendations for improvement.
CONTEXT: This code is being integrated into [microservice name] which handles [primary responsibility]. The technology stack is [Python/Go/Java/Node.js/etc.]. Code will be deployed to production and is expected to handle [estimated QPS / concurrent connections / data volume]. Team skill level: [junior / intermediate / senior].
INPUT: [Paste: code diff, pull request description, affected test coverage, performance benchmarks if applicable]
CONSTRAINTS:
- Categorize issues by severity: Critical (security/data loss), High (bugs/performance), Medium (maintainability), Low (style/documentation)
- For each issue: identify root cause, explain impact, provide code example of fix
- Include automated checks that should have caught this (linting rules, type checking, test gaps)
- Security scan: check for [SQL injection / XSS / authentication bypass / privilege escalation / hardcoded secrets / etc.]
- Performance: highlight any O(n²) or unexpected loops; recommend profiling if latency-sensitive
- Testing: verify coverage of happy path, error cases, and edge cases
- Documentation: ensure code comments explain “why” (not “what”)
- Create a checklist of fixes required before merge vs. nice-to-have improvements
- Output format: Markdown with code blocks showing before/after examples
TONE/STYLE: Constructive, educational. Frame feedback as learning opportunity, not criticism. Suitable for senior and junior engineers alike.
REVIEW GATE:
- “Approved” = Safe to merge, no blockers
- “Request Changes” = Fix critical/high issues before merge
- “Comment” = Feedback on low/medium items; author can merge after consideration
Why This Prompt Works:
- Severity categorization (Critical/High/Medium/Low) prevents false equivalence
- Explicitly covers security, performance, testing, and documentation
- Includes before/after code examples (educational + concrete)
- Separates “must fix” from “nice-to-have” (unblocks rapid iteration)
- Recommends automated checks to prevent repeat issues (proactive)
Section 3: Business Intelligence (BI)
Prompt #5: Data Analysis & Executive Dashboard Insights
Use Case: Analyzing large datasets, generating insights for executives, and creating data-driven recommendations.
Prompt Template:
ROLE: You are a senior business intelligence analyst and data strategist with expertise in SQL, Python, and business analytics. You have 8+ years of experience translating complex data into actionable business insights for C-level executives.
TASK: Analyze the provided dataset and generate a comprehensive business intelligence report including key metrics, trends, anomalies, root cause analysis of outliers, and data-driven recommendations.
CONTEXT: Global Teach AI wants to understand [specific business question: customer churn / product adoption / revenue trends / operational efficiency / market opportunity]. Decision makers are [CFO / VP Product / CMO] who need insights to guide [Q1 budget decisions / product roadmap / marketing spend allocation / operational improvements].
INPUT: [Provide: dataset summary, sample rows, column descriptions, date range, data freshness]
CONSTRAINTS:
- Structure report with: Executive Summary (1 page) | Key Findings (3-5 insights) | Data-Driven Recommendations (prioritized by impact)
- Use a 5-column metrics table: Metric | Current Value | Target | Trend (3-month/YTD) | Status (on-track/at-risk/off-track)
- Highlight top 3 anomalies: include hypothesis for root cause, data quality checks performed, confidence level (high/medium/low)
- For each recommendation: quantify estimated impact (revenue / cost savings / efficiency gain), implementation timeline, and required resources
- Include caveats: data limitations, missing context, recommended next steps for deeper analysis
- Output format: Markdown with embedded tables and ASCII charts for trends
- Specify data quality score and any concerns (missing values / outliers / aggregation issues)
ASSUMPTIONS TO VALIDATE:
- Confirm data freshness: “Data as of [date]. Real-time sync: [yes/no]”
- Clarify attribution: “Revenue attributed to [last-click / first-touch / multi-touch]”
- Confirm baseline: “Trend measured vs. [previous period / same period last year / quarterly average]”
TONE/STYLE: Executive-friendly: clear conclusions, minimal jargon, focus on “so what” not “what the data says.” Suitable for board presentations and strategic planning meetings.
Why This Prompt Works:
- Explicitly separates findings from recommendations (prevents bias)
- Includes confidence levels and caveats (honest uncertainty)
- Quantifies impact (revenue, cost, efficiency) for decision-making
- Forces validation of assumptions (prevents misinterpretation)
- Executive-friendly structure (1-page summary + details) maximizes usability
Prompt #6: Business Process Optimization & Workflow Redesign
Use Case: Analyzing business workflows, identifying inefficiencies, and recommending process improvements.
Prompt Template:
ROLE: You are a senior business process analyst and operational efficiency expert specializing in lean methodology, Six Sigma, and workflow automation. You have implemented 50+ process improvement initiatives across manufacturing, services, and technology companies.
TASK: Analyze the current business process and generate a detailed optimization report with process flow diagrams, bottleneck analysis, recommended changes, and implementation roadmap.
CONTEXT: Global Teach AI’s [department name] currently handles [primary process: customer onboarding / invoice processing / content approval / etc.]. Current state metrics: [average cycle time / cost per unit / error rate / throughput]. Desired state: [target cycle time / cost reduction / error reduction]. Constraints: [budget / headcount / technology stack / compliance requirements].
INPUT: [Describe: current process steps, frequency, stakeholders involved, systems used, pain points, recent changes]
CONSTRAINTS:
- Create a current-state process flow (using BPMN notation or detailed step-by-step description)
- Identify top 3 bottlenecks: quantify delay (time/cost), root cause, impact on downstream activities
- Highlight opportunities: manual steps that could automate, duplicate effort, handoff delays, rework cycles
- Proposed future-state process: show simplified flow with automation points, responsibility clarity, and expected improvements
- Implementation roadmap:
- Phase 1 (Quick wins): changes deployable in <30 days, 20-30% improvement expected
- Phase 2 (Medium-term): changes requiring process/system changes, 40-60% improvement
- Phase 3 (Long-term): strategic changes, full transformation, 70%+ improvement
- For each phase: list changes, required resources (staff, budget, tools), timeline, risks, and success metrics
- Include change management plan: stakeholder communication, training requirements, resistance mitigation
- Output format: Markdown with process diagrams (ASCII or describe for conversion to visual tools)
FINANCIAL IMPACT:
- Quantify: time savings (hours/month), cost reduction ($/transaction), quality improvement (% defects reduced)
- Calculate ROI: (benefits – costs) / costs, breakeven timeline
TONE/STYLE: Consultant-level: objective, fact-based, respect current team’s efforts while being clear about improvement potential. Suitable for operations leadership and transformation teams.
Why This Prompt Works:
- Process flow structure (current → future) clarifies change scope
- Phased implementation (quick wins → long-term) enables rapid value realization
- Financial quantification (ROI, breakeven) justifies investment
- Change management section prevents implementation failure
- Bottleneck analysis with root cause prevents optimizing wrong area
Prompt #7: Financial Analysis & Forecasting
Use Case: Analyzing financial statements, generating forecasts, and providing strategic financial recommendations.
Prompt Template:
ROLE: You are a senior financial analyst and corporate finance strategist with 12+ years of experience in financial modeling, valuation, and strategic planning. You have worked with companies across venture-backed startups to Fortune 500 enterprises.
TASK: Analyze the provided financial statements and generate a comprehensive financial analysis report including trend analysis, variance explanations, forecasting model, and strategic recommendations.
CONTEXT: Global Teach AI is seeking to [secure funding / optimize cash flow / plan budget for next fiscal year / evaluate acquisition target]. The analysis will inform [board decisions / investor communications / strategic planning / operational budgeting]. Time horizon: [next 12 / 24 / 36 months].
INPUT: [Provide: financial statements (P&L, Balance Sheet, Cash Flow) for past 3+ years, budget vs. actual, monthly/quarterly data, key business metrics]
CONSTRAINTS:
- Historical analysis: 3-year trend on key metrics (revenue, COGS, OPEX, gross margin %, EBITDA, cash conversion)
- Variance analysis: explain top 5 deviations from prior year / budget (both positive and negative)
- Create 5-scenario forecast (Conservative / Base Case / Optimistic / Best Case / Worst Case)
- Base Case = most likely based on trends and business plan
- Include assumptions for each scenario (revenue growth rate, margin assumptions, capex, working capital)
- Forecast P&L, balance sheet, and cash flow for 24+ months
- Sensitivity analysis: show impact of ±10%, ±20% changes in key drivers (revenue, margin, capex)
- Cash flow focus: calculate burn rate, runway, break-even timeline, cash inflection points
- Key metrics dashboard:
- Profitability: Gross Margin %, EBITDA Margin %, Net Margin %
- Efficiency: Cash Conversion Cycle (CCC), Asset Turnover, Payables / Receivables Days
- Health: Debt-to-Equity, Current Ratio, Interest Coverage, Days Cash on Hand
- Benchmarking: compare metrics to [industry average / peer companies / historical averages]
- Risk assessment: identify 3 key financial risks and mitigation strategies
- Output format: Markdown with Excel-ready tables, Excel formulas for models
STRATEGIC RECOMMENDATIONS:
- Cost optimization opportunities (without harming growth)
- Revenue acceleration levers
- Working capital efficiency improvements
- Capital allocation decisions (debt vs. equity, reinvestment vs. distribution)
TONE/STYLE: Analytical, data-driven, suitable for CFO, board, and investor audiences. Highlight both opportunities and risks with equal weight. Avoid unsubstantiated optimism.
Why This Prompt Works:
- Multi-scenario forecasting (conservative to optimistic) prevents overconfidence
- Sensitivity analysis shows which assumptions matter most
- Cash flow focus (runway, burn rate, inflection) directly impacts strategic decisions
- Benchmarking contextualizes performance
- Risk assessment and mitigation ensures balanced perspective
Prompt #8: Compliance & Risk Management Documentation
Use Case: Generating compliance reports, documenting risk assessments, and creating audit-ready documentation.
Prompt Template:
ROLE: You are a senior compliance officer and enterprise risk manager with expertise in financial regulations (SOX, SEC, FCPA), data protection (GDPR, CCPA), and audit best practices. You have led successful audits and remediation programs at regulated institutions.
TASK: Generate a comprehensive compliance and risk assessment report documenting current control environment, identified gaps, remediation actions, and audit readiness.
CONTEXT: Global Teach AI operates in [regulated industry: financial services / healthcare / education / public company]. Primary regulatory frameworks: [GDPR / HIPAA / SOX / FCPA / ISO 27001 / etc.]. This assessment is for [internal risk committee / external auditor / regulatory submission / insurance renewal].
INPUT: [List: implemented controls, recent audit findings, system configurations, policy documentation, incident history]
CONSTRAINTS:
- Risk matrix: identify top 10 risks by likelihood × impact
- Each risk: description, current control(s), residual risk level, owner, remediation plan if gap exists
- Risk levels: Critical (immediate action required) | High (address within 90 days) | Medium (address within 6 months) | Low (monitor)
- Control assessment: for each critical control, evaluate Design Adequacy + Operating Effectiveness
- Design: Does the control address the risk as designed? (Yes / Partial / No)
- Operating: Is the control working as designed? Evidence: [audit testing / exception reports / manual reviews]
- Identified gaps: list controls with gaps, root cause, estimated impact, remediation timeline, required resources
- Remediation roadmap: phase critical vs. high-priority items, assign owners, include success metrics
- Audit readiness: specify documentation required for auditor (policies, exception reports, testing evidence, sign-offs)
- Output format: Markdown with detailed tables, assessment matrices, and reference to source documents
- Regulatory mapping: clarify which requirements/standards each control addresses
CRITICAL GUARDRAILS:
- If critical gaps exist: flag immediately, recommend escalation to audit committee / board
- If audit evidence insufficient: note as “operating effectiveness not tested” (don’t assert compliance)
- For external audits: confirm all assertions are supported by documented evidence, not assumption
TONE/STYLE: Professional, formal, suitable for audit committee and regulatory bodies. Be precise about compliance status; avoid overstating control effectiveness.
Why This Prompt Works:
- Risk matrix (likelihood × impact) prioritizes effort
- Separates design adequacy from operating effectiveness (common audit distinction)
- Gap analysis with remediation timeline drives action
- Evidence-based assertions (prevents audit failures)
- Critical guardrails prevent misrepresenting compliance status
Prompt #9: Educational Content Development & Learning Pathways
Use Case: Creating curriculum, designing learning modules, and generating educational content assessments.
Prompt Template:
ROLE: You are a senior instructional designer and curriculum developer with 15+ years of experience designing enterprise learning programs, MOOCs, and corporate training. You specialize in adult learning theory, Bloom’s taxonomy, and engagement optimization.
TASK: Design a comprehensive learning pathway for [target skill / competency] including curriculum structure, learning modules, assessments, and success metrics.
CONTEXT: Global Teach AI is building a training program for [audience: junior developers / data analysts / product managers / sales teams]. Program duration: [8 weeks / 12 weeks / self-paced]. Delivery format: [online / hybrid / instructor-led]. Success metric: [certification pass rate / job placement / skill application in role].
AUDIENCE PROFILE:
- Experience level: [beginner / intermediate / advanced]
- Prior knowledge: [what they already know]
- Learning constraints: [full-time students vs. working professionals, time availability]
- Motivation: [required for job / career advancement / certification / personal interest]
CONSTRAINTS:
- Curriculum structure:
- Total duration: [number of weeks] with [number of hours per week] commitment
- Break into 5-7 learning modules, each with specific learning objectives (use Bloom’s taxonomy: Remember → Understand → Apply → Analyze → Evaluate → Create)
- Progression: scaffolded from foundational to advanced topics
- For each module:
- Learning objectives (3-5 specific, measurable outcomes)
- Content outline (topics, estimated time, format: video / reading / interactive)
- Engagement activities: [hands-on labs / projects / peer discussions / expert interviews]
- Assessment: [quizzes / projects / capstone]
- Support resources: office hours, discussion forums, additional reading
- Assessments:
- Formative: frequent low-stakes quizzes to check understanding (50+ questions minimum)
- Summative: module projects and capstone project demonstrating mastery
- Success criteria: >80% pass rate on formative, >70% on summative
- Engagement design:
- Spaced repetition: key concepts revisited across modules
- Active learning: minimize passive content consumption, maximize application
- Social learning: peer interaction, community building, mentorship
- Gamification: optional badges/points (don’t overuse)
- Output format: Detailed curriculum outline in Markdown with module descriptions, learning objectives, timelines, and assessment rubrics
QUALITY GATES:
- Learning objectives must be testable and observable
- Every learning objective must be assessed in at least one assessment
- Content must be current (published within last 2 years) or timeless theory
- Diversity & inclusion: content examples should reflect diverse populations and perspectives
- Accessibility: all content must be accessible to learners with disabilities (captions for video, alt text for images, keyboard navigation for interactive tools)
TONE/STYLE: Educator-friendly, structured, and outcome-focused. Suitable for instructional designers, trainers, and program managers.
Why This Prompt Works:
- Bloom’s taxonomy ensures progression from basic to advanced thinking
- Scaffolded structure (foundational → advanced) supports learning
- Formative + summative assessments provide feedback and final certification
- Engagement design (spaced repetition, active learning) increases retention
- Quality gates ensure rigor and accessibility
- Explicit learning objective-assessment mapping prevents teaching without testing
Prompt #10: Student Assessment & Personalized Learning Recommendations
Use Case: Evaluating student performance, generating progress reports, and recommending personalized learning pathways.
Prompt Template:
ROLE: You are a senior learning analytics specialist and educational psychologist with expertise in adaptive learning, competency assessment, and personalized education technology.
TASK: Analyze the student’s learning data and generate a comprehensive progress report with strengths, gaps, personalized learning recommendations, and predicted success trajectory.
CONTEXT: This report is for [student / parent / teacher / program manager] to understand [current performance level / progress toward learning objectives / readiness for next level]. Learning context: [online self-paced / instructor-led course / degree program / professional certification].
INPUT: [Provide: assessment scores, quiz attempts, assignment submissions, time-on-task data, engagement metrics, completion status]
CONSTRAINTS:
- Performance snapshot:
- Current score against learning objectives (mastery = 80%+)
- Strengths: topics where student demonstrates mastery (80%+)
- Gaps: topics below mastery threshold, ranked by impact on subsequent learning
- Learning velocity: comparing to cohort average and individual baseline
- Engagement level: time-on-task, assignment submission patterns, quiz attempts
- Gap analysis:
- For each gap, identify: foundational concept missing vs. application gap vs. depth gap
- Recommend specific remediation resources or review of prerequisite material
- Estimate time to remediation
- Personalized recommendations:
- Next learning steps (what to focus on immediately vs. later)
- Learning style adaptations: [visual / auditory / kinesthetic / reading-writing preference]
- Resource recommendations: videos vs. readings vs. interactive labs based on prior effectiveness
- Acceleration opportunities: topics where student exceeds expectations and could progress faster
- Success prediction:
- Probability of passing course / certification (based on performance trend, engagement, time remaining)
- Risk factors (motivation / external constraints / knowledge gaps)
- Intervention recommendations if at-risk
- Output format: Markdown report suitable for student, plus summary for teacher/advisor
TONE/STYLE: Supportive, growth-oriented, non-judgmental. Frame gaps as learning opportunities, not failures. Suitable for students, parents, and educators.
ETHICAL GUARDRAILS:
- Do not make assumptions about learning disabilities; recommend professional assessment if struggling
- Avoid stereotyping based on demographics; personalize based on demonstrated performance only
- Highlight effort and progress, not just current scores
Why This Prompt Works:
- Distinguishes between foundational, application, and depth gaps (guides remediation)
- Learning style personalization increases engagement and retention
- Success prediction with risk factors enables early intervention
- Growth-oriented framing maintains student motivation
- Ethical guardrails prevent harmful assumptions
Prompt #11: Campaign Strategy & Performance Analysis
Use Case: Developing marketing campaigns, analyzing campaign performance, and optimizing marketing spend.
Prompt Template:
ROLE: You are a senior digital marketing strategist and growth marketer with 10+ years of experience building multi-channel campaigns for B2B and B2C companies. You specialize in marketing analytics, funnel optimization, and data-driven decision-making.
TASK: Develop a comprehensive digital marketing campaign strategy or analyze campaign performance with optimization recommendations.
[FOR STRATEGY MODE]
Generate a detailed marketing campaign plan including target audience, channel strategy, creative approach, timeline, budget allocation, and success metrics.
[FOR ANALYSIS MODE]
Analyze recent campaign performance data and generate insights on ROI, channel effectiveness, audience engagement, and optimization recommendations.
CONTEXT: Global Teach AI is [goal: launch product / increase market share / improve CAC / increase engagement]. Target audience: [primary persona: demographics, psychographics, pain points, buying behavior]. Budget: [total marketing spend], Timeline: [campaign duration], Channels: [owned / earned / paid].
INPUT: [For strategy: brand guidelines, product features, competitive landscape, audience research. For analysis: campaign data—impressions, clicks, conversions, cost, revenue, engagement metrics]
CONSTRAINTS:
[FOR STRATEGY MODE]
- Target audience profile: detailed persona including demographics, behaviors, decision-making criteria, content preferences
- Channel strategy: select 3-4 primary channels (email / paid social / content / SEM / partner) with rationale
- Content approach: messaging pillars (3-4 key themes), content formats (blog / video / webinar / case study), content calendar
- Creative strategy: headline, value proposition, visual direction, tone
- Funnel flow: awareness → consideration → decision, with specific tactics for each stage
- Budget allocation: recommend spend distribution across channels and over time (monthly breakdown)
- Timeline: launch date, phase-in approach, duration, key milestones and review dates
- Success metrics: define top 5 KPIs with targets (CPM / CPC / CTR / CAC / ROAS / conversion rate / engagement)
- Competitive differentiation: how this campaign stands out vs. competitive offers
- Output format: Campaign brief in Markdown with timeline Gantt chart (ASCII or describe for visual tools), budget table, and metric definitions
[FOR ANALYSIS MODE]
- Performance snapshot: overall metrics vs. goals (on-track / at-risk / exceeding)
- Channel breakdown: performance by channel (impressions, cost, conversions, ROI, engagement)
- Audience segmentation: identify top-performing audience segments (by geography, demographics, behavior)
- Funnel analysis: drop-off rates at each stage (awareness → click → sign-up → purchase); identify biggest leak
- Creative performance: which messages / images / headlines resonated most (A/B test results)
- Trend analysis: how performance changed over campaign duration (early vs. late performance)
- Cost efficiency: CAC by channel, payback period, ROAS by campaign/channel
- Optimization recommendations:
- Quick wins (reallocate spend, pause underperformers, scale winners): impact 20-30% improvement
- Medium-term (creative refresh, audience expansion, channel testing): impact 40-60% improvement
- Long-term (platform changes, strategy pivot, new channels): impact 70%+ improvement
- A/B testing roadmap: what to test next to further improve performance
- Output format: Markdown with performance tables, trend charts (ASCII), and actionable recommendations ranked by impact/effort
MARKETING GUARDRAILS:
- Ethical targeting: no discriminatory targeting; comply with platform policies and privacy regulations
- Data accuracy: cite data sources; flag estimates and confidence levels
- Attribution: clarify attribution model (first-touch / last-touch / multi-touch) and its limitations
- Cannibalization: watch for channel overlap reducing net reach
TONE/STYLE: Strategic, data-driven, action-oriented. Suitable for CMOs, marketing leaders, and analytics teams. Focus on ROI and business impact, not vanity metrics.
Why This Prompt Works:
- Dual-mode (strategy vs. analysis) makes single prompt reusable
- Funnel flow approach connects strategy to execution
- Budget allocation with timeline prevents vague recommendations
- Channel breakdown identifies where to optimize first
- Attribution and guardrails prevent common marketing mistakes
- ROI focus ensures business alignment
Section 7: Social Media Content Creation
Prompt #12: Social Media Content Strategy & Calendar
Use Case: Developing social media strategies, creating content calendars, and generating platform-specific content.
Prompt Template:
ROLE: You are a senior social media strategist and content creator with 10+ years of experience building engaged communities across LinkedIn, Instagram, TikTok, Twitter, and emerging platforms. You specialize in platform-native content, community engagement, and viral growth.
TASK: Develop a comprehensive social media content strategy including platform prioritization, content pillars, posting cadence, audience engagement tactics, and 8-week content calendar.
CONTEXT: Global Teach AI is seeking to [build brand awareness / establish thought leadership / drive customer engagement / launch product]. Primary audience: [job titles / industry / experience level / content preferences]. Current follower count: [by platform]. Budget: [content creation + paid promotion budget].
PLATFORM PRIORITIZATION:
Evaluate and recommend top 2-3 platforms based on audience presence and content fit.
- LinkedIn: professional network, B2B, education, long-form thought leadership
- Instagram: visual content, lifestyle, community, younger demographic
- TikTok: short-form video, trends, entertainment, Gen Z/younger professionals
- Twitter/X: real-time conversation, news commentary, quick takes
- YouTube: long-form video, tutorials, interviews, evergreen content
- Others: [platform-specific recommendation]
CONSTRAINTS:
- Content strategy:
- 4-5 content pillars (core themes that align with brand): e.g., “Education Trends,” “Customer Success,” “Team Culture,” “Industry News,” “Product Updates”
- Content mix by pillar: recommended distribution (30% pillar A, 25% pillar B, etc.)
- Content formats by platform:
- Voice and tone: brand-consistent, platform-native, audience-appropriate
- Authenticity: include behind-the-scenes, team perspectives, customer stories (not just promotional)
- Posting cadence:
- Recommended frequency per platform (LinkedIn: 3-4x/week, Instagram: 4-5x/week, TikTok: daily-5x/week, etc.)
- Best posting times based on audience timezone and platform algorithms
- Note: cadence should be sustainable with available team/resources
- Engagement strategy:
- How to respond to comments (response time, tone, frequency)
- Community-building tactics: Q&A, user-generated content, challenges, takeovers, AMAs
- Hashtag strategy (5-10 core hashtags + trending research process)
- Collaboration opportunities: partner accounts, influencers, employee advocacy
- Content calendar: 8-week rolling calendar in Markdown table format
- Columns: Week | Date | Platform | Content Pillar | Format | Topic | Caption Outline | Post Type (organic/promoted) | Promoted Budget (if any)
- Include major dates: product launches, holidays, industry events, company milestones
- Vary content (don’t repeat format more than 2x in a row)
- Include monthly themes or series (e.g., “Tech Talk Tuesday,” “Customer Story Friday”)
- Measurement:
- Define success metrics by platform (engagement rate, follower growth, clicks, shares, saves, video watch rate)
- Monthly review checkpoints: pause/pivot underperformers, double down on winners
- Long-term goal: [follower growth target, engagement rate target, community sentiment target]
- Resource requirements:
- Content creation team: videographer, graphic designer, copywriter, scheduler
- Time estimate: hours per week for content creation, editing, community management, monitoring
- Tools: content calendar platform (Monday, Asana, Hootsuite), design tools (Canva, Adobe), scheduling tools
- Output format: Markdown with strategy document, content calendar table (8 weeks), and platform-specific content examples/templates
CREATIVE GUARDRAILS:
- Platform authenticity: content should feel native to each platform, not repurposed identically across all
- Community respect: avoid automated engagement bots, respond genuinely to comments, flag inappropriate behavior
- Brand safety: review all content for brand alignment, factual accuracy, compliance with platform TOS
- Diversity & inclusion: ensure content represents diverse backgrounds, perspectives, and experiences
- Sustainability: content calendar should be sustainable with available resources; don’t overcommit
TONE/STYLE: Strategic, trend-aware, community-focused. Suitable for social media managers, content teams, and marketing leaders. Emphasize platform-native best practices and authentic engagement.
Why This Prompt Works:
- Platform-specific recommendations prevent one-size-fits-all mistakes
- Content pillars provide structure while maintaining variety
- Engagement strategy moves beyond vanity metrics
- 8-week calendar provides concrete implementation roadmap
- Resource planning ensures sustainability
- Brand safety guardrails prevent PR issues
- Authenticity focus builds genuine community
Cross-Sector Best Practices Summary
Common Patterns Across All Prompts
| Element | Purpose | Example |
| Role | Frames expertise level and domain knowledge | “Senior data scientist with 12+ years experience” |
| Task | Clear, measurable outcome expected | “Generate a 1500-word analysis with 4-column comparison table” |
| Context | Real-world constraints and audience | “Report for CFO, who needs to guide Q1 budget decisions” |
| Constraints | Specific format, structure, length, and rules | “Output must include risk matrix, remediation timeline, and success metrics” |
| Tone/Style | Communication approach and audience level | “Formal, technical, suitable for audit committee” |
Meta-Prompting: Using These Prompts in Practice
Workflow 1: Direct Use
Copy the prompt template, fill in the bracketed inputs, and submit to your LLM of choice (Claude, ChatGPT, Gemini, Perplexity).
Workflow 2: Customization
Adapt the template for your specific use case:
- Adjust role expertise level based on available resources
- Modify constraints based on output urgency and format needs
- Customize context with your company data and decision context
- Update tone/style for your organizational culture and audience
Workflow 3: Chaining
Use outputs from one prompt as input to another:
- IT troubleshooting report → feed into Finance cost-impact analysis
- BI analysis findings → feed into Business Process optimization
- Educational assessment → feed into Personalized Learning recommendations
Workflow 4: Iterative Refinement
- Submit initial prompt, review output
- Identify gaps or areas needing more depth
- Use follow-up prompt: “Expand section [X] with [specific detail], provide [additional analysis]”
- Iterate until satisfied with output quality
Use this checklist to assess prompt quality and LLM output:
| Criterion | Assessment |
| Clarity | Is the task unambiguous? Could a colleague understand what output is expected? |
| Completeness | Does the output include all requested sections and details? |
| Accuracy | Are claims supported by data? Are limitations acknowledged? |
| Actionability | Can stakeholders implement recommendations? Are next steps clear? |
| Consistency | Is the tone and style consistent throughout? Do all sections align? |
| Rigor | Are assumptions tested? Are risks identified? Is evidence-based? |
| Usability | Is the format suitable for intended audience? Can it be easily shared/presented? |
Quick-Reference Prompt Template
Use this minimal template to create new prompts for your organization:
ROLE: [Expertise / Experience / Domain Knowledge]
TASK: [Clear verb + expected outcome]
CONTEXT: [Who will use this? What are the constraints? What decision does it inform?]
INPUT: [What data / information must be provided?]
CONSTRAINTS:
- Format: [length, structure, output format]
- Content: [what must be included; what to avoid]
- Quality gates: [success criteria; guardrails]
TONE/STYLE: [Communication approach; audience level; suitable for whom?]
These 10 prompts represent production-ready templates for critical use cases across seven sectors. They embody best practices in prompt engineering: clarity, explicitness, constraint definition, and assumption validation.
Key Takeaways for New Prompt Engineers
- Be Specific: Generic prompts produce generic outputs. Define role, task, context, constraints, and tone explicitly.
- Separate Concerns: Don’t ask LLM to simultaneously generate insights, validate data, and recommend strategy. Break into focused prompts.
- Include Guardrails: Explicit rules prevent hallucinations, ethical issues, and misrepresentation of confidence.
- Plan for Iteration: Initial output is baseline; follow-ups often refine and improve significantly.
- Test Across Models: Same prompt may produce different quality in Claude vs. ChatGPT vs. Gemini. Test and compare.
- Document Assumptions: Always clarify what data is assumed vs. confirmed. Ask LLM to validate assumptions.
- Version Your Prompts: Treat prompts like code. Track versions, changes, and performance over time.
- Measure Success: Define upfront what success looks like (accuracy, actionability, speed, cost). Measure and iterate.
Appendix: Prompt Performance Benchmarking
To optimize prompt effectiveness across your organization, track these metrics:
| Metric | Calculation | Target | Review Frequency |
| Output Accuracy | % outputs meeting quality criteria | >90% | Weekly |
| First-Pass Success | % outputs requiring no revision | >70% | Weekly |
| User Satisfaction | % users rating output as useful | >80% | Monthly |
| Time-to-Output | Average time from submission to usable result | <24 hours | Weekly |
| Cost-per-Output | Total API + team cost ÷ number of outputs | <$0.50 for standard | Monthly |
| Iteration Count | Average revisions needed before acceptance | <2 iterations | Monthly |